AI知识集锦01:AI如何识别猫?一份图解指南。
神经网络推动了当今的人工智能热潮。要理解它们,我们只需要一张地图、一只猫和几千个维度。说明
AI如何识别猫?一份图解指南。
看一张猫的图片,你会立刻认出它是一只猫。但试着编程让计算机识别猫的照片,你会很快意识到这远非易事。你需要编写代码来精确指出无数猫在具有独特背景和从不同相机角度拍摄的照片中共享的本质特征。那么你该从哪里开始呢?
如今,计算机能够轻松识别猫的照片,但这并不是因为某位聪明的程序员找到了提取“猫性”本质的方法。相反,它们是依靠神经网络来完成这一任务的。神经网络是一种人工智能模型,通过观察数百万甚至数十亿的图像实例来学习识别图片。神经网络还可以极为流畅地生成文本,精通复杂的游戏,甚至在数学和生物学中解决各种问题——这些都是在没有任何明确指示的情况下完成的。
研究人员对神经网络的内部运行机制仍有许多未解之谜,但它们并非完全不可理解。通过将神经网络拆解为基本构成模块,我们可以探究它们是如何学会分辨一只虎斑猫和一块桌布的。
一个简单的分类器
猫的识别是研究人员所谓的“分类任务”的一个例子。给定一个对象——在这里是一张图片——目标是将其分配到正确的类别中。有些分类任务比判断“猫”还是“非猫”要简单得多。我们来考虑一个有趣的例子,涉及到两个虚构的地区,三角形领地和正方形州。

你得到一个新点,这个点由其经度和纬度坐标描述,你需要判断它属于哪个区域。但你手头并没有显示边界的地图。你只有一组已知属于这两个区域的点。
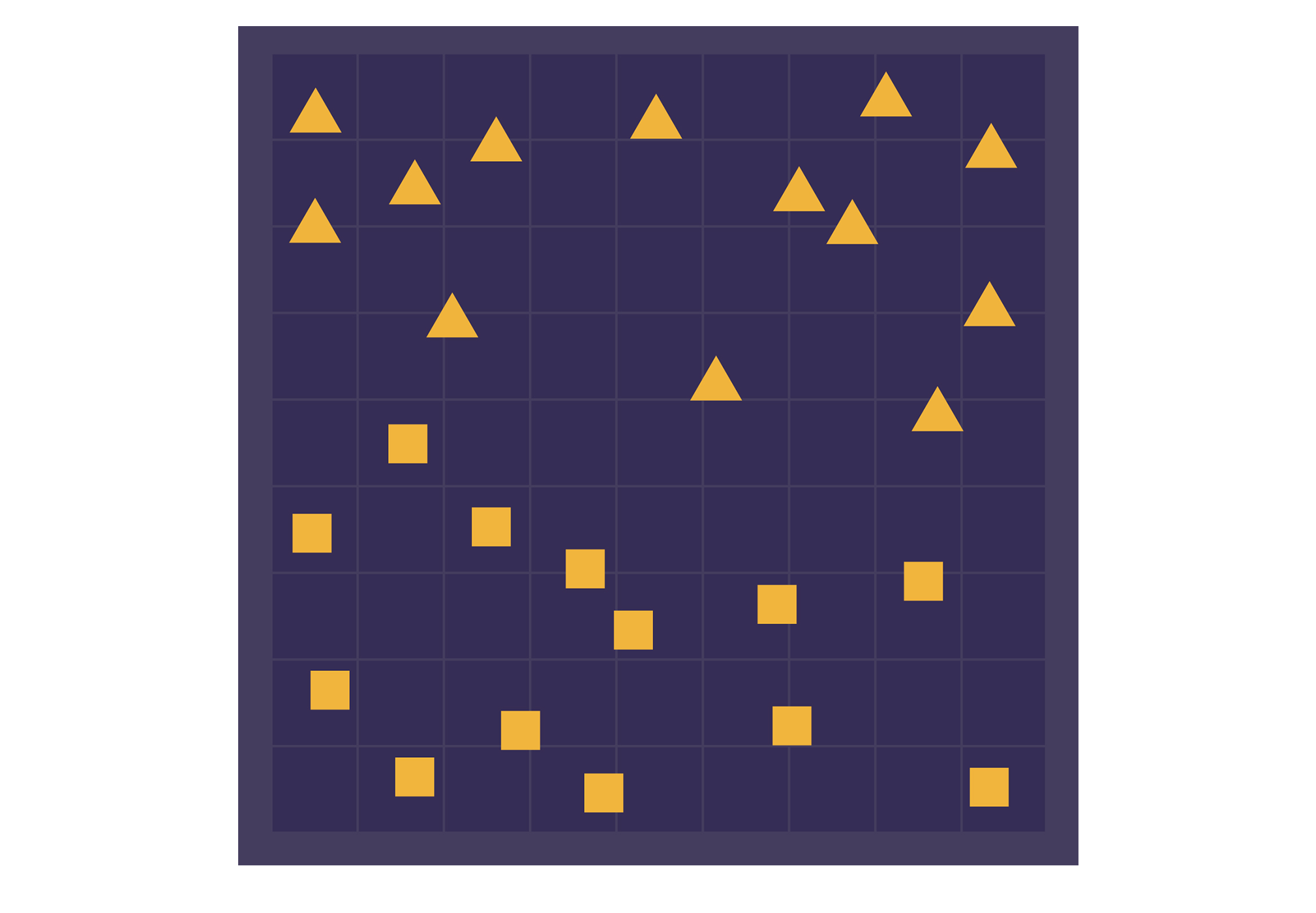
要建立一个能够自动分类未知点的“分类器”系统,你需要先画出一个边界。之后,当你得到一个新的点时,分类器只需要看它位于边界的哪一侧即可。
但是,你如何决定该在哪里画这个边界呢?这就要用到神经网络了。它们会根据最初给出的已知数据点,找到最有可能的分类边界。
在我们理解这个过程是如何工作的前提下,我们需要暂时放下地图,来了解神经网络的基本构建模块,也就是“神经元”。神经元其实就是一个数学函数,有多个输入和一个输出。你输入一些数字,它就会输出一个新的数字,仅此而已。
更简单来说,神经元的输出通常会非常接近于0或1。 具体接近哪一个,取决于输入以及另一组被称为“参数”的数字。 对于有两个输入的神经元来说,它具有三个参数。 其中两个叫作“权重”(weights),用于决定每个输入对输出的影响程度。 第三个参数叫作“偏置”(bias),它决定了神经元整体偏向输出0还是1。
weights权重,权重通常用于描述神经元输入的相对重要性,在机器学习和神经网络中常见。
bias指偏置或偏差,在机器学习中,它是一个影响模型预测结果的参数。
现在,让我们来看看输入和输出之间的关系。下面的三幅图分别展示了三组不同参数设置下的神经元。 当输入发生变化时,每种情况下神经元的输出都会在某条边界上迅速从0跃升到1。 在这些图中,这条边界始终是一条直线。参数决定了这条直线的位置和角度。

为了创建一个能够判断新点属于正方形州还是三角形领地的分类器,我们需要调整这条直线,使其准确表示两个区域之间的边界。 在这里,如果输出值接近0,我们认为该点属于正方形州;如果输出值接近1,则认为它属于三角形领地。
要调整这条直线,我们需要通过一个叫作“训练”的过程来调整神经元的参数。 第一步是将这些参数设置为随机值,这意味着神经元一开始画出的边界线通常与实际的分界线相差甚远。

在训练过程中,我们将每个已知数据点的经度和纬度作为输入,传递给神经元。 神经元会根据当前参数输出一个结果,并将该结果与真实值进行比较。 有时,神经元会给出正确的答案。
其他的数据点则会被错误地分类。
每当神经元给出了错误的答案,自动化算法就会稍微调整神经元的参数,使分界线朝向错误点的方向移动得更近一些。

算法会在训练数据上反复多次执行这一过程。最终,我们会得到一组参数,使得这条直线能够最接近地拟合实际的分界线形状。
最后,我们就可以把这个分类器用到之前未参与训练的新数据上了。虽然它并不是百分之百准确,但大多数情况下都能给出正确的答案。
神经元网络
单个神经元在我们的简单示例中表现得还不错,但这是因为三角形领地和正方形州之间的真实边界本身就接近一条直线。 面对更复杂的问题,我们需要使用许多彼此相连的神经元组成的“神经网络”。 和单个神经元一样,神经网络本质上也是一种数学函数:输入一些数字,输出则是另外一些数字。
在神经网络中,神经元被分为若干组,这些组被称为“层”。
每一层可以包含任意数量的神经元,神经网络也可以有任意多层。每一层中神经元的输出将作为下一层神经元的输入。
大型神经网络拥有许多参数:每个神经元都有一个偏置(bias),每两个神经元之间的每条连接都有一个权重(weights)。这些额外的参数让网络能够学习到更为复杂的边界。
boundaries边界,在神经网络中,边界通常指神经元之间的连接或决策区域,这些边界可以是复杂的曲线而非直线。
举个例子,假设你依然在做地图分类任务,但这次两个区域之间的真实边界远远不是一条直线。

我们可以尝试训练一个单神经元分类器来近似这个分界线,但效果通常不会很好。一般来说,更大的神经网络能够完成更加复杂的任务,不过它们也需要更多的训练数据。

从地图到猫咪
我们已经看到,通过增加神经元的数量,可以让神经网络变得更加强大。不过,到目前为止,我们只讨论了具有两个输入的网络。实际上,神经网络的输入数量没有限制。大多数实际的应用任务都需要拥有许多输入的网络。
在之前的例子中,神经元的两个输入分别是地图上某个点的经度和纬度。神经网络的输入数字同样可以表示其他类型的数据。例如,0到1之间的一个数字可以代表单个像素的灰度值。
这意味着任意一对像素都可以在一个二维空间中表示为一个点。
如果我们把一对像素的某个特征(比如它们的坐标、颜色值、亮度差异等)映射到两个维度上,那么每一对像素就能对应平面上的唯一一个点。
常见于图像处理、计算机视觉或数据分析中,例如:
- 像素坐标分析:取两个像素的横纵坐标 与 ,把它们组成一对,然后映射到二维空间(比如只取 与 ,或 与 等)。
- 颜色空间分析:比较两个像素的 RGB 值,把某两个通道的数值作为横纵坐标画在图上。
- 特征关系可视化:研究像素之间的关系时,将成对数据放到二维散点图中观察分布规律。
假设我们有一幅图像,考虑其中任意两个像素 A 和 B,我们只关注它们的 水平位置( 坐标):
像素 A 的 坐标是 10,像素 B 的 坐标是 50 那么这一对像素可以表示为二维空间中的一个点 (10, 50)。 如果遍历图像中所有像素对,就会得到很多这样的点,分布在二维平面上,从而可以进行聚类、分布分析等操作。
✅ 总结: 这一种数据映射方法——把像素对的特征转化为二维坐标,从而在图上直观地呈现它们的关系或分布。
同样,像素的三元组可以对应到三维空间中的一个点。
更多的像素意味着需要更多的维度。虽然我们无法直接可视化三维以上的空间,但研究者们已经开发出一些方法,能够以类似于“观察三维空间的二维快照”的方式,间接地查看这些抽象空间的三维表示。比如,9个维度就可以用来表示一个 3×3 网格上的各种不同图案。
为了说明这种方法的实际用处,我们不妨将输入数量从9个跃升到2500个,假设它们分别对应一个 50×50 的像素网格。 如此规模的像素排列,可以组成各种有意义的图案,比如猫的照片。每一张猫咪照片都对应于这个 2,500 维空间中的一个点。

而这个空间中的其他点,则对应于咖啡杯的图片。

只要有足够的数据点,我们就可以训练一个大型神经网络,让它学会区分猫和非猫。

所有猫咪照片都分布在这个2500维空间中的某个复杂区域内。训练算法会不断调整神经网络的参数,直到找到包围这一难以想象的区域的边界。

经过训练的神经网络便能够正确分类那些未曾见过的新图像。这样,我们就得到了一个可以“识别”猫咪图片的网络。
不止于猫
我们的猫咪识别网络拥有大量的神经元和输入,但只有一个输出。如果我们增加输出节点,就可以训练神经网络识别多种类别的物体,而不仅仅是猫。每一个类别都对应于这个 2,500 维空间中的不同区域。更复杂的图像识别网络已被广泛应用于天体物理学、细胞生物学、医学等许多领域。
神经网络不仅可以完成分类任务,还能处理更多类型的问题。像 ChatGPT 这样的大型语言模型,就是建立在神经网络之上的,其输入和输出的数字分别用来表示单词。最新的神经网络规模非常庞大,拥有数十亿甚至上万亿个参数。这导致我们很难准确理解网络内部各个部分究竟在做什么。试图揭示大型神经网络内部的运行机理,是当今许多研究人员面临的重大挑战。